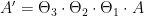OpenCV 3.0
Occi vi mostrerò come compilare le OpenCV con il supporto per le schede grafiche NVIDIA.
Prima di tutto scarichiamo le OpenCV 3.0 dal loro repository su GitHub: https://github.com/Itseez/opencv.
Installiamo i sorgenti dove più ci piace, per questo esempio io le metterò sul Desktop.
Poi scarichiamo CMake che al momento della stesura di questo articolo è alla versione 3.3.0. Installiamolo. Io ho utilizzato il Win32 Installer.
Scarichiamo ovviamente il CUDA toolkit dal sito della NVIDIA e installiamolo. Al momento di stesura dell’articolo siamo alla versione 7.0. Io ho installato il Windows 8.1 local installer.
Lanciamo CMake e andiamo a dare il percorso dei sorgenti delle OpenCV e della cartella dove vogliamo generare la solution di Visual Studio 2013 per la compilazione:

Spuntare “Grouped” e “Advanced”, cliccare su “Configure” e scegliere “Visual Studio 12 2013 Win64” e poi “Finished” e aspettare il termine.

Al termine dovremmo vedere “configure done” scritto nella finestra di console di CMake ma la parte centrale probabilmente verrà evidenziata di rosso:

Espandiamo il nodo BUILD nella finestra rossa ed eliminiamo la spunta da BUILD_DOCS.
Nel mio caso l’errore deo Config era il fatto che non trova Doxygen. Semplicemente così dovremmo risolvere il conflitto.
Però io ho eliminato anche la generazione degli esempi per velocizzare un po’ la compilazione togliendo la spunta da BUILD_EXAMPLES

Controlliamo che nel nodo CMAKE il valore di CMAKE_LINKER sia il linker di Visual Studio 2013 (v12).

Controlliamo che nel nodo CUDA non sia selezionato (eventualmente togliamo la sputa da) CUDA_ATTACH_VS_BUILD_RULE_TO_CUDA_FILE.
Questo flag server se si eseguono Build in parallelo.

Nel nodo WITH controlliamo che siano selezionati (altrimnenti mettiamo la spunta anche in) WITH_CUBLAS, WITH_CUDA, WITH_OPENGL.
Intanto che compiliamo con CUDA compiliamo anche le CUDA Basic Linear Algebra Subroutines (cuBLAS) e il supporto per le OPEN_GL.

Ripremiamo “Configure” per fare il refresh e per vedere che questa volta la finestra centrale sia “bianca”.
Vi ricordo che ora è bianca perchè abbiamo tolto la spunta da BUILD_DOCS che cercava Doxygen e non per le altre configurazioni fatte.

Se la finestra centrale è bianca e abbiamo “Configure done” allora è tutto Ok e possiamo cliccare su “Generate” per creare la soluzione Visual Studio.

A questo punto dopo “Generating done” possiamo chiudere CMake e andare ad aprire la solution nella cartella dove abbiamo detto di crearla che nel mio caso è: C:\Users\fabio\Desktop\buildCuda

Aprite la solutione, lanciate ALL_BUILD in Debug o Release e andate a prendere un caffè 🙂
Non vi è bastato vero il caffè? Sul mio PC impiega circa un’ora a Build (i7, 12GB ram, SSD HD).

Una volta finito di Compilare lanciate la INSTALL.
Lanciate INSTALL che trovate in (CMakeTargets) per avere nella directory “install” le dll e librerie appena compilate


Ecco dove troverete le vostre DLL e LIB delle OpenCV compilate con CUDA

Io ora ho compilato in Debug.
Lanciando anche la compilazione in Release vedrete insieme le librerie di debug (*d.dll, *d.lib) assieme a quelle di release (*.dll, *.lib).
OpenCV 2.4.9
Per le OpenCV 2.4.9 il procedimento è praticamente identico, però ho dovuto impostare il CUDA_GENERATION dicendo esplicitamente la mia architettura ‘Kepler‘

Altrimenti avevo l’errore di compilazione: Unsupported gpu architecture ‘compute_11’
Ho letto comunque che se si setta l’architettura specifica anche con le OpenCV 3.0 la compilazione è molto più veloce perchè non vengono compilati i file .cu per le altre architatture.
Senza specificarlo invece vengono compilati i .cu per tutte le architatture (GPU): Kepler, Fermi, etc…
E ho dovuto modificare il file NCV.cu (opencv-2.4.9\modules\gpu\src\nvidia\core\NCV.cu), andando ad includere il package “algorithm”:
#include <algorithm>

Altrimenti mi dava l’errore: ‘max’ undefined error.
Mi piace:
Mi piace Caricamento...
 .
.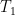 nell’origine del punto
nell’origine del punto  , una rotazione rispetto all’origine
, una rotazione rispetto all’origine  di
di 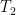 che riporti A al suo posto 🙂
che riporti A al suo posto 🙂
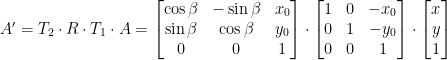

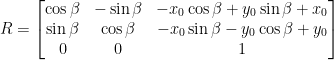
 è:
è:

 nel sistema di riferimento omogeneo diventa
nel sistema di riferimento omogeneo diventa 
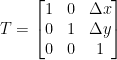




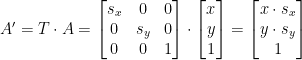
 ,
, 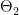 ,
, 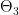 che vengono fatte in sequenza: Prima
che vengono fatte in sequenza: Prima